Nuestra tecnología
Iniciamos la nueva era de la previsibilidad 
Cambio de concepto
Los problemas del mundo real suelen ser muy dinámicos. Por ejemplo, el comportamiento de un consumidor puede cambiar a medida que envejece, un grupo de personas puede cambiar de opinión sobre un producto o un partido político, o los ataques que recibe una red pueden variar a medida que se crean nuevas barreras, etc.
Aprender con datos cuya distribución cambia con el tiempo es una tarea difícil, ya que los algoritmos convencionales de aprendizaje automático y estadística asumen que la distribución de los datos es estática.
Esto significa que, si se produce un cambio después del proceso de generación de un modelo estadístico o de aprendizaje automático convencional, este pierde su eficacia, por lo que es necesario reiniciar todo el proceso de generación de un nuevo modelo a medida que surgen nuevos datos.

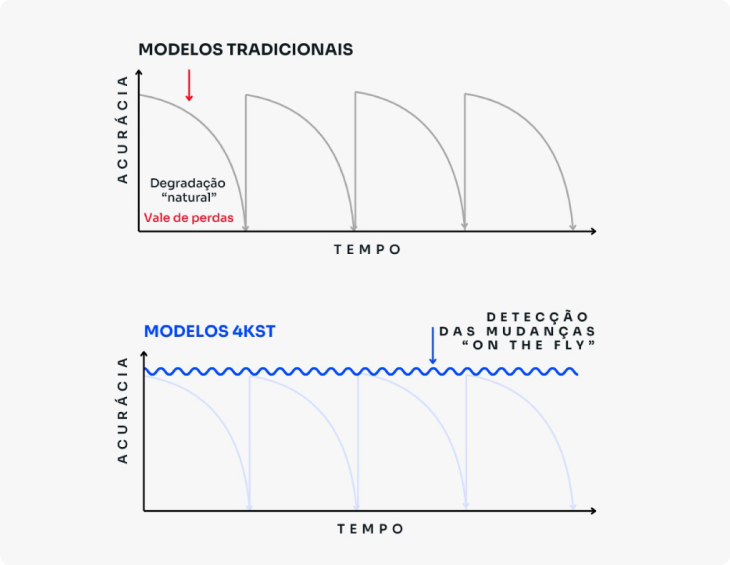
Diferencial 4kst
4kst se especializa en tecnologías para la minería de flujos de datos (Data Stream Mining).
En general, los flujos cuyos datos cambian con el tiempo se denominan flujos evolutivos (evolving data streams), mientras que los flujos en los que la distribución de datos permanece inalterada se denominan flujos estacionarios. Esto no significa que trabajemos exclusivamente con aplicaciones en tiempo real o basadas en flujos de datos.
De hecho, todo lo que ocurre en el orden del tiempo puede tratarse como un flujo de eventos en secuencia cronológica, y lo que se almacena en bases de datos puede leerse en ese mismo orden y aplicarse en nuestra tecnología.
Hay muchos aspectos que hay que tener en cuenta sobre los cambios que pueden producirse en un flujo de datos, incluyendo su causa, frecuencia y el punto en el que ha cambiado la distribución de los datos. La causa de un cambio puede estar relacionada con las variables ocultas (contexto oculto) del problema de aprendizaje.
Por ejemplo, los atributos disponibles que describen a un cliente pueden no contener todas las variables posibles que afectan su comportamiento, simplemente porque estas variables son esporádicas o muy complejas, como los índices macroeconómicos, que pueden afectar la vida económica de muchos clientes.
Diferencias entre el enfoque 4kst
y el enfoque Batch
| CRITERIOS DE EVALUACIÓN | ENFOQUE POR LOTES | ENFOQUE 4KST |
|---|---|---|
| Dimensionalidad de los datos – Número de instancias |
Limitada: asume que todos los datos están en memoria; requiere muestreo. | Ilimitada: procesa una instancia a la vez, sin necesidad de almacenarla ni limitar su número. |
| Dimensionalidad de los datos – Número de atributos |
Limitada: la mayoría de los algoritmos trabajan con una cantidad limitada de atributos. | Ilimitada: procesa grandes cantidades de variables (a escala de miles) de forma natural. |
| Representación de datos | Limitada: Muchos algoritmos solo funcionan con variables discretas. | Ilimitada: procesa variables numéricas o discretas de forma natural. |
| Dependencia del analista de Datos y conocimientos previos |
Alta: en general, se requiere un amplio conocimiento del dominio para generar modelos útiles. | Baja: se pueden generar rápidamente modelos precisos sin necesidad de realizar estudios exhaustivos ni modelar datos. |
| Tiempo de producción del modelo | Elevado: El modelado, la selección y el preprocesamiento de datos pueden llevar meses. | Muy bajo: los algoritmos seleccionan automáticamente los datos útiles para modelos precisos. |
| Tiempo de procesamiento | Elevado: Los algoritmos tienen una complejidad elevada y necesitan mucho tiempo para procesar incluso conjuntos pequeños de datos. | Muy bajo: diseñado para procesar continuamente flujos continuos e infinitos de datos. |
| Duración del ciclo de vida del modelo | En resumen: los entornos dinámicos hacen que los modelos de predicción queden obsoletos rápidamente, ya que se degradan (son estáticos). | Tiempo indeterminado: las variaciones y los cambios en las distribuciones y el rendimiento se detectan automáticamente y se utilizan para adaptar automáticamente el modelo. |
| Pérdida de productividad por depreciación | Elevado: el tiempo que tarda el analista o el experto en la materia en detectar el deterioro del modelo y volver a entrenarlo puede generar pérdidas de gran volumen | Mínima: Los algoritmos son capaces de aprender de forma continua, manteniendo una alta productividad y precisión a lo largo del tiempo |
Este proceso se conoce como «
» (aprendizaje de flujo de datos).
Data Stream Learning
Donde los datos fluyen como un «río continuo» y el algoritmo se adapta a cada nueva entrada,
sin necesidad de detener, reprocesar o reiniciar el patrón.
¿El resultado? Modelos que no se degradan, no envejecen y mantienen la asertividad incluso ante contextos inéditos.
4kst y el mercado de ML
En los últimos años, el aprendizaje automático se ha convertido en un recurso tecnológico muy codiciado por prácticamente todas las empresas. Se han superado algunas barreras técnicas, lo que ha hecho que el aprendizaje automático sea accesible a un número cada vez mayor de organizaciones.
Parte de las causas de esta difusión a gran escala entre microempresas, pequeñas, medianas y grandes empresas se deriva del interés y las iniciativas de gigantes del sector tecnológico, como Google, Amazon, IBM y Microsoft, por vender ML como servicio, generando lo que hoy se conoce como Machine Learning as a Service (MLaaS). Estas empresas han encapsulado algoritmos y herramientas de ML en servicios web, llegando a una gran cantidad de clientes.
Ninguna de estas plataformas ofrece algoritmos de minería de datos en tiempo real, que son el objetivo principal de 4kst. Las razones de esta carencia son numerosas. Por citar algunas:
- Ruptura de paradigma: los productos consolidados en el mercado de ML, como los de las grandes empresas de TI mencionadas anteriormente, ofrecen algoritmos típicamente por lotes a sus clientes. De esta manera, ya sea con la ayuda de consultores o de forma independiente, los modelos se generan y se ponen en producción periódicamente, lo que requiere una gran dependencia de profesionales especializados en análisis de datos. Por otro lado, los algoritmos de Data Stream Mining suelen funcionar de forma casi autónoma, seleccionando variables e instancias con métodos automatizados, lo que mantiene modelos de alta eficacia en producción durante largos ciclos de vida.
- Facturación/coste de la nube: los algoritmos por lotes consumen muchos recursos informáticos, memoria para el almacenamiento de datos y procesamiento para la generación de modelos. Esto es bueno para los proveedores de nube, pero malo para los clientes. Los streamers son mucho más eficientes y reducen significativamente la necesidad y los costes de la nube.
- Facturación/coste de consultoría: los grandes actores del ML ofrecen servicios de consultoría para el desarrollo de aplicaciones especializadas y prevén etapas de actualización de modelos en sus contratos, lo que aumenta significativamente los gastos de los clientes. Un enfoque streamer reduce este esfuerzo, ya que realiza la actualización de modelos de forma automática, lo que reduce, en consecuencia, los costes de ML.
| Producto | Aprendizaje adaptativo (sobre la marcha) Desviación conceptual | Aprendizaje incremental (sin límite de eventos) Escala | Aprendizaje rápido sobre la marcha (frente al aprendizaje profundo) | Bajo consumo computacional | Cloud SaaS | Soporte |
|---|---|---|---|---|---|---|
| IA Adaptativa 4kst | ||||||
| Aprendizaje profundo (IBM, Google, Amazon, Microsoft) | ||||||
| Aprendizaje por lotes (IBM, Google, Amazon, Microsoft) * | ||||||
| Aprendizaje por lotes de código abierto * |
La tabla anterior presenta una comparación entre la tecnología 4kst y las tecnologías de ML disponibles en el mercado. Aunque algunas plataformas ofrecen técnicas sencillas de actualización automática de modelos, por ejemplo, parametrizando la generación de nuevos modelos por frecuencia temporal o cantidad de observaciones, siguen utilizando el modelo por lotes en la mayoría de los casos. Por otro lado, los algoritmos incrementales disponibles, basados en Deep Learning o Lazy Learning (aprendizaje basado en instancias), son demasiado costosos desde el punto de vista computacional, lo que los hace prohibitivos en aplicaciones de flujos de datos. Además, dado que su aprendizaje es lento debido a su estructura de solución, procesar una nueva instancia (o actualizar el modelo) puede ser más lento que la frecuencia de entrada de nuevas instancias, lo que provoca un desbordamiento del modelo e imposibilita el seguimiento del flujo real de datos, por ejemplo, el procesamiento de millones de transacciones de pago y sus respectivas actualizaciones en un modelo antifraude.

Los datos son infinitos
y nuestra visión ilimitada
Entra en el universo 4kst y
transforma los datos en decisiones poderosas.
Testimonios de quienes ya han elegido 4kst
Testimonios reales de clientes que han transformado sus resultados con nuestra IA adaptativa.
-

Nos quedamos muy sorprendidos con las cifras.
«Los resultados fueron tan buenos que incluso sospeché, pero lo confirmé y eran correctos: la morosidad pasó del 33 % al 13 % en un mercado, y del 37 % al 19 % en otro. No conozco a nadie que lo haga como lo hace 4kst, con ese grado de personalización y evolución».
Thiago Lucas Queiroz de Sá
Gerente de Relaciones y Experiencia del Cliente
VOX
-
4kst me da el remedio exacto para mi enfermedad.
«La puntuación no es genérica, sino personalizada, pensada y específica. El modelo se desarrolla con nuestros datos y no solo con los del mercado. Es más específico. 4kst me da el remedio exacto para mi enfermedad. Es 4kst la que está reduciendo nuestra morosidad. Ya hemos alcanzado una reducción del 30 %. Para mejorar esta cifra, necesitamos recortar el crédito, pero no podemos hacer que el negocio sea inviable».
Dirección Financiera
Todescredi
-
El modelo de 4kst trajo consigo una toma de decisiones personalizada.
«Antes hacíamos el análisis de forma manual. Mi preocupación era tener una puntuación sólida que tuviera en cuenta todas nuestras particularidades: mi cartera, el historial de los clientes y su clasificación de riesgo, mi situación económica, las nueve empresas del grupo y los distintos productos implicados. El modelo de 4kst aportó una toma de decisiones personalizada, ¡fue muy importante!».
Eliane Vieira
Gerente de políticas de crédito y cobranza
Edenred