Our Technology
We are entering a new era of predictability 
Change of concept
Real-world problems are usually highly dynamic. For example, a consumer's behavior can change as they get older, a group of people can change their opinion of a product or political party, or the attacks a network receives can vary as new barriers are created, and so on.
Learning from data whose distribution changes over time is a challenging task, since conventional machine learning and statistical algorithms assume that the data distribution is static.
This means that if a change occurs after a conventional statistical or machine learning model has been generated, the model loses its effectiveness, making it necessary to restart the entire process of generating a new model as new insights emerge.

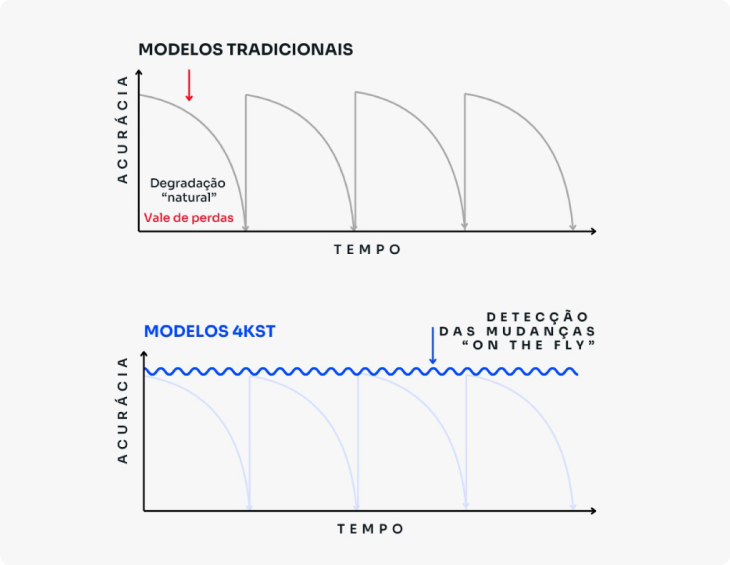
4kst differential
4kst specializes in Data Stream Mining technologies.
In general, streams whose data changes over time are called evolving data streams, while streams in which the data distribution remains unchanged are called stationary streams. This doesn't mean that we work exclusively with real-time or data stream-based applications.
In fact, everything that happens in the order of time can be treated as a flow of events in chronological sequence, and what is stored in databases can be read in that same order and applied to our technology.
There are many aspects to consider about the changes that can occur in a data stream, including their cause, frequency and the point at which the data distribution changed. The cause of a change can be related to the hidden variables (hidden context) of the learning problem.
For example, the available attributes that describe a customer may not contain all the possible variables that affect their behavior, simply because these variables are sporadic or very complex, such as macroeconomic indices, which can affect the economic lives of many customers.
Differences between the 4kst approach
and the Batch approach
| EVALUATION CRITERIA | BATCH APPROACH | 4KST APPROACH |
|---|---|---|
| Data Dimensionality - Number of Instances |
Limited: assumes all data is in memory - requires sampling | Unlimited: processes one instance at a time, without having to store it or limit its number |
| Data Dimensionality - Number of Attributes |
Limited: most algorithms work with a limited number of attributes | Unlimited: processes large numbers of variables (scale of thousands) naturally. |
| Data representation | Limited: Many algorithms only work with discrete variables | Unlimited: processes numerical or discrete variables naturally |
| Data Analyst Dependency and Background Knowledge |
High: in general, a lot of domain knowledge is needed to generate useful models | Low: accurate models can be generated quickly without extensive data study and modeling |
| Model Production Time | High: Data modeling, selection and pre-processing can take months | Very low: algorithms automatically select useful data for accurate models |
| Processing Time | High: Algorithms are highly complex and require a lot of time to process even small sets of data. | Very low: designed to continuously process endless streams of data |
| Duration of the Model Life Cycle | Too short: dynamic environments make predictive models obsolete quickly, as they degrade (they are static) | Indefinite: variations and changes in distributions and performance are automatically detected and used to automatically adapt the model |
| Loss of productivity due to depreciation | High: The time required for the analyst or domain expert to identify model degradation and retrain the model can result in significant losses | Minimum: Algorithms are capable of continuous learning, maintaining high productivity and accuracy over time |
This process is known as
Data Stream Learning
Where the data flows like a "continuous river" and the algorithm adapts to each new input,
without the need to stop, reprocess or restart the pattern.
The result? Models that don't degrade, don't age and maintain assertiveness even in the face of unprecedented contexts.
4kst and the ML Market
In recent years, ML has become a highly sought-after technological resource for practically all companies. Some technical barriers have been overcome, making Machine Learning accessible to a growing number of organizations.
Part of the reason for this large-scale dissemination among micro, small, medium and large companies stems from the interest and initiatives of giants in the technology sector, such as Google, Amazon, IBM and Microsoft, to sell ML as a service, generating what is now known as Machine Learning as a Service (MLaaS). These companies have encapsulated ML algorithms and tools in web services, reaching a large-scale customer audience.
None of these platforms offer data stream mining algorithms, which are the focus of 4kst. There are numerous reasons for this gap. To name a few:
- Paradigm shift: the products consolidated in the ML market, such as those of the large IT companies mentioned above, typically provide their customers with batch algorithms. In this way, whether with the help of consultants or independently, models are generated and put into production periodically, requiring a high level of dependence on professionals specialized in data analysis. On the other hand, Data Stream Mining algorithms generally work almost autonomously, selecting variables and instances with automated methods, keeping highly effective models in production for long life cycles.
- Cloud billing/costs: batch algorithms consume a lot of computing resources, memory for data storage and processing for model generation. This is good for cloud providers, but bad for customers. Streamers are much more efficient and significantly reduce cloud requirements and costs.
- Billing/consultancy costs: the big ML players offer consultancy services for the development of specialized applications and include model update steps in their contracts, significantly increasing their clients' costs. A streamer approach reduces this effort by updating models automatically, thereby reducing ML costs.
| Product | Adaptive Learning (On the Fly) Concept Drift | Incremental learning (unlimited events) Scale | Rapid On-the-Fly Learning (versus Deep Learning) | Low computing power | Cloud Saas | Support |
|---|---|---|---|---|---|---|
| Adaptive AI 4kst | ||||||
| Deep Learning (IBM, Google, Amazon, Microsoft) | ||||||
| Batch Learning (IBM, Google, Amazon, Microsoft) * | ||||||
| Open Source Batch Learning * |
The table above shows a comparison between 4kst technology and the ML technologies available on the market. Although some platforms offer simple techniques for automatically updating models, for example by parameterizing the generation of new models by time frequency or number of observations, they continue to use the batch model in most cases. On the other hand, the incremental algorithms available, based on Deep Learning or Lazy Learning, are too costly from a computational point of view, making them prohibitive in data flow applications. What's more, since they take a long time to learn due to their solution structure, processing a new instance (or updating the model) can be slower than the frequency of new instances coming in, causing the model to overflow and making it impossible to keep up with the actual flow of data, for example, processing millions of payment transactions and their respective updates in an anti-fraud model.

Data is infinite
and our vision unlimited
Enter the 4kst universe and
transform data into powerful decisions.
Testimonials from those who have chosen 4kst
Real testimonials from customers who have transformed their results with our Adaptive AI
-

We were extremely surprised by the figures
"The results were so good that I was suspicious, but I checked and they were right: defaults went from 33% to 13% in one market, from 37% to 19% in another. I don't know anyone who does it the way 4kst does, with this degree of personalization and evolution."
Thiago Lucas Queiroz de Sá
Relationship and Customer Experience Manager
VOX
-
4kst gives me the exact remedy for my illness
"The score isn't off-the-shelf, it's personalized, thought out and specific. The model is developed using our data and not just market data. It's more niche. 4kst gives me the exact remedy for my illness. It is 4kst that is leading to a reduction in our default rates. We've already achieved a 30% reduction. To improve this figure we need to cut credit, but we can't make the business unviable."
Financial Management
Todescredi
-
The 4kst model brought personalized decision-making
"We used to do the analysis manually. My pain was to have a robust score that took into account all our particularities: my portfolio, the history of clients and their risk ranking, where I am economically inserted, the 9 companies in the group and the various products involved. The 4kst model provided personalized decision-making, which was very important!"
Eliane Vieira
Credit and collection policy manager
Edenred