Nossa Tecnologia
Iniciamos a nova era da previsibilidade 
Mudança de conceito
Os problemas do mundo real, em geral, são altamente dinâmicos. Por exemplo, o comportamento de um consumidor pode mudar à medida que envelhece, um grupo de pessoas pode alterar sua opinião sobre um produto ou partido político, ou ainda, os ataques que uma rede recebe podem variar conforme novas barreiras são criadas e assim por diante.
Aprender com dados cuja distribuição muda ao longo do tempo é uma tarefa desafiadora, já que os algoritmos convencionais de aprendizagem de máquina e estatística assumem que a distribuição de dados é estática.
Isso significa que se uma mudança ocorre posteriormente ao processo de geração de um modelo estatístico ou de aprendizagem de máquina convencional, ele perde sua eficiência, sendo necessário reiniciar todo o processo de geração de um novo modelo quando novas verdades vão surgindo.

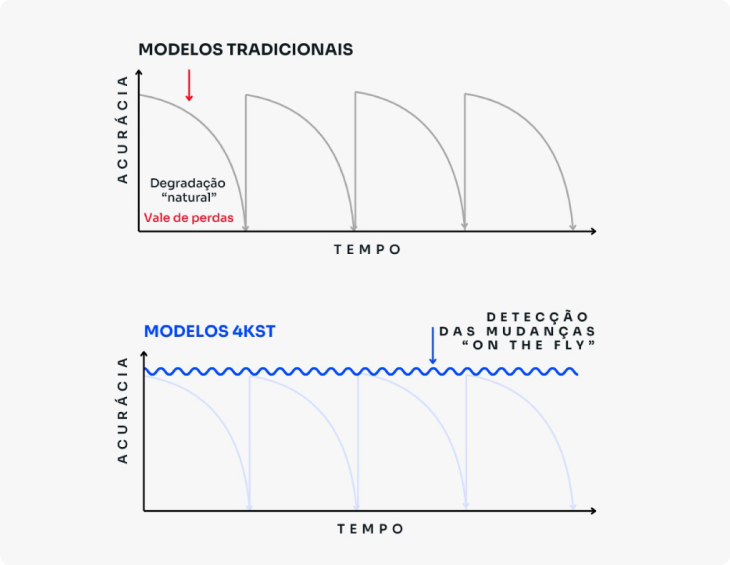
Diferencial 4kst
A 4kst é especializada em tecnologias para mineração de fluxos de dados (Data Stream Mining).
Em geral, os fluxos cujos dados se alteram ao longo do tempo são chamados de fluxos evolutivos (evolving data streams), enquanto os fluxos em que a distribuição de dados permanece inalterada são denominados fluxos estacionários. Isso não significa que trabalhemos exclusivamente com aplicações em tempo real ou baseadas em data stream.
Na verdade, tudo o que acontece na ordem do tempo pode ser tratado como um fluxo de eventos em sequência cronológica, e o que está armazenado em bases de dados pode ser lido nessa mesma ordem e aplicado em nossa tecnologia.
Há muitos aspectos a considerar sobre as mudanças que podem ocorrer em um fluxo de dados, incluindo sua causa, frequência e o ponto em que a distribuição de dados mudou. A causa de uma mudança pode estar relacionada às variáveis ocultas (contexto oculto) do problema de aprendizagem.
Por exemplo, os atributos disponíveis que descrevem um cliente podem não conter todas as variáveis possíveis que afetam seu comportamento, simplesmente porque essas variáveis são esporádicas ou muito complexas, como os índices macroeconômicos, que podem afetar a vida econômica de muitos clientes.
Diferenças entre a abordagem 4kst
e a abordagem Batch
| CRITÉRIO DE AVALIAÇÃO | ABORDAGEM BATCH | ABORDAGEM 4KST |
|---|---|---|
| Dimensionalidade dos Dados – Número de Instâncias |
Limitada: assume que todos os dados estão em memória – exige amostragem | Ilimitada: processa uma instância por vez, sem necessitar armazená-la ou limitar em número |
| Dimensionalidade dos Dados – Número de Atributos |
Limitada: maioria dos algoritmos trabalha com quantidade limitada de atributos | Ilimitada: processa grandes quantidades de variáveis (escala de milhares) naturalmente. |
| Representação dos Dados | Limitada: Muitos algoritmos trabalham apenas com variáveis discretas | Ilimitada: processa variáveis numéricas ou discretas naturalmente |
| Dependência de Analista de Dados e Background Knowledge |
Elevada: em geral, muito conhecimento do domínio é necessário para geração de modelos úteis | Baixa: modelos precisos podem ser gerados rapidamente sem extenso estudo e modelagem de dados |
| Tempo de Produção do Modelo | Elevado: Modelagem, seleção e pré-processamento de dados podem levar meses | Muito baixo: algoritmos fazem automaticamente seleção de dados úteis para modelos precisos |
| Tempo de Processamento | Elevado: Algoritmos tem elevada complexidade e necessitam de muito tempo para processar mesmo conjuntos pequenos de dados | Muito Baixo: feito para processar continuamente fluxos contínuos e infinitos de dados |
| Duração do Ciclo de Vida do Modelo | Muito curto: ambientes dinâmicos tornam os modelos de previsão obsoletos rapidamente, pois degradam (são estáticos) | Tempo Indeterminado: variações e alterações de distribuições e performance são automaticamente detectadas e utilizadas para adaptação automática do modelo |
| Perda de Produtividade por Depreciação | Elevada: o tempo necessário para o analista ou especialista do domínio determinar a depreciação do modelo e retreiná-lo pode gerar perdas de grande volume | Mínima: Algoritmos são capazes de aprender continuamente, mantendo elevada produtividade e precisão ao longo do tempo |
Esse processo é conhecido como
Data Stream Learning
Onde os dados fluem como um “rio contínuo” e o algoritmo se adapta a cada nova entrada,
sem necessidade de parar, reprocessar ou reiniciar o padrão.
O resultado? Modelos que não degradam, não envelhecem e mantêm a assertividade mesmo diante de contextos inéditos.
4kst e o Mercado de ML
Nos últimos anos, ML se tornou um recurso tecnológico bastante almejado por praticamente todas as empresas. Algumas barreiras técnicas vêm sendo superadas, tornando o Machine Learning acessível a um número crescente de organizações.
Parte das causas dessa disseminação em larga escala, entre micro, pequenas, médias e grandes empresas, deriva do interesse e das iniciativas de gigantes do setor de tecnologia, como Google, Amazon, IBM e Microsoft, em vender ML como serviço, gerando o que se conhece hoje por Machine Learning as a Service (MLaaS). Essas empresas encapsularam algoritmos e ferramentas de ML em serviços web, alcançando um público de clientes em larga escala.
Nenhuma dessas plataformas oferece algoritmos de Data Stream Mining, que são o foco da 4kst. As razões desse gap são inúmeras. Para citar algumas:
- Ruptura de paradigma: os produtos consolidados no mercado de ML, como os das grandes empresas de TI citadas acima, disponibilizam algoritmos tipicamente batch aos seus clientes. Dessa forma, seja com auxílio de consultoria ou de forma independente, os modelos são gerados e colocados em produção periodicamente, exigindo elevada dependência de profissionais especializados em análise de dados. Por outro lado, algoritmos de Data Stream Mining geralmente trabalham de forma quase autônoma, selecionando variáveis e instâncias com métodos automatizados, mantendo modelos de alta eficácia em produção por longos ciclos de vida.
- Faturamento/custo com cloud: algoritmos batch consomem muitos recursos computacionais, memória para armazenamento de dados e processamento para geração de modelos. Isso é bom para os fornecedores de cloud, mas péssimo para os clientes. Os streamers são muito mais eficientes e reduzem significativamente a necessidade e os custos com cloud.
- Faturamento/custo com consultoria: os grandes players de ML oferecem serviços de consultoria para o desenvolvimento de aplicações especializadas e preveem etapas de atualização de modelos em seus contratos, aumentando significativamente os gastos dos clientes. Uma abordagem streamer reduz esse esforço, pois realiza a atualização de modelos de forma automática, diminuindo, por consequência, os custos de ML.
| Produto | Aprendizado Adaptativo (On the Fly) Concept Drift | Aprendizado Incremental (ilimitado em eventos) Escala | Aprendizado Rápido On the Fly (versus Deep Learning) | Baixo Consumo Computacional | Cloud Saas | Suporte |
|---|---|---|---|---|---|---|
| IA Adaptativa 4kst | ||||||
| Deep Learning (IBM, Google, Amazon, Microsoft) | ||||||
| Batch Learning (IBM, Google, Amazon, Microsoft) * | ||||||
| Open Source Batch Learning * |
A Tabela acima apresenta uma comparação entre a tecnologia 4kst e as tecnologias de ML disponíveis no mercado. Embora algumas plataformas disponibilizem técnicas simples de atualização automática de modelos, por exemplo, parametrizando a geração de novos modelos por frequência temporal ou quantidade de observações, elas continuam utilizando o modelo batch na maioria dos casos. Por outro lado, os algoritmos incrementais disponíveis, baseados em Deep Learning ou Lazy Learning (Aprendizado Baseado em Instância), são demasiadamente custosos do ponto de vista computacional, tornando-se proibitivos em aplicações de fluxos de dados. Além disso, como seu aprendizado é demorado devido à sua estrutura de solução, processar uma nova instância (ou atualizar o modelo) pode ser mais lento do que a frequência de entrada de novas instâncias, causando overflow do modelo e impossibilitando o acompanhamento do fluxo real de dados, por exemplo, o processamento de milhões de transações de pagamento e suas respectivas atualizações em um modelo antifraude.

Os dados são infinitos
e nossa visão ilimitada
Entre no universo 4kst e
transforme dados em decisões poderosas.
Depoimentos de quem já escolheu a 4kst
Depoimentos reais de clientes que transformaram seus resultados com nossa IA Adaptativa
-

Ficamos extremamente surpresos com os números
“Os resultados foram tão bons que até desconfiei, mas confirmei e estavam corretos: a inadimplência passou de 33% para 13% em uma praça, de 37% para 19% em outra. Não conheço ninguém que faça do jeito que a 4kst faz, esse grau de personalização e evolução.”
Thiago Lucas Queiroz de Sá
Gerente de Relacionamento e Customer Experience
VOX
-
A 4kst dá o remédio exato para minha doença
“O score não é de prateleira, é personalizado, pensado e específico. O modelo é desenvolvido com os nossos dados e não só com os de mercado. É mais nichado. A 4kst dá o remédio exato para minha doença. É a 4kst que está levando à redução da nossa inadimplência. Já chegamos nos 30% de redução. Para melhorar esse número precisamos cortar o crédito, mas não podemos inviabilizar o negócio.”
Diretoria Financeira
Todescredi
-
O modelo da 4kst trouxe uma tomada de decisão personalizada
"Antes fazíamos a análise de forma manual. Minha dor era ter um score robusto que considerasse todas as nossas particularidades: a minha carteira, o histórico dos clientes e o ranking de risco deles, onde eu estou inserida economicamente, as 9 empresas do grupo e os vários produtos envolvidos. O modelo da 4kst trouxe uma tomada de decisão personalizada, foi muito importante!"
Eliane Vieira
Gerente de políticas de crédito e cobrança
Edenred